



INTRODUCTION
•
✦
研究介绍
✦
•
研究背景
Background
双相障碍期间的抑郁发作会大大增加患者发病率及死亡率。然而,精神类疾病具有的复杂性病理因素导致其临床治疗方案一直存在高度异质性,这使得根据患者的既往病史、诊疗史及个人特质进行个性化治疗变得异常困难。大语言模型在识别罕见或难以解决的临床场景上显示出巨大潜力,可用于精准医疗的临床探索。
2024年3月13日,美国麻省总医院(Massachusetts General Hospital)哈佛医学院精神病学教授、美国麻省总医院量化健康中心创始人兼主任、美国麻省总医院实验药物与诊断中心主任Roy H. Perlis及其研究团队在 Neuropsychopharmacology期刊发表了题为:Clinical decision support for bipolar depression using large language models的研究论文。
研究意义
Significance
该研究发现,以专科循证指南为提示的大语言增强模型显著地提高了模型在选择双相障碍抑郁发作的最佳药物治疗方案的准确性,表现优于非增强模型和社区医生,并在性别和种族偏见的检验中显示出较小的差异,可以作为临床决策支持 工具,帮助临床医生选择最佳的药物治疗方案。
研究创新性地将治疗指南整合到模型的提示中,发现增强模型在药物治疗方案的选择上表现优于非增强模型和社区医生。
总之,本研究强调了使用大语言模型作为临床决策支持工具的潜在优势,建议进行前瞻性研究和随机对照试验以验证其有效性和安全性,并建议进一步完善相关措施,避免医生产生对这类模型的过度依赖。
METHODS
•
✦
研究方法
✦
•
临床情景生成
Vignette generation
基于两个学术医疗中心和附属社区医院的电子健康记录数据,使用概率模型生成50个反映双相障碍抑郁发作的临床情景文本。每个情景文本首先包括了基本的社会人口学信息,旨在使情景更加逼真,同时保持足够大的亚组,以便进行二次分析以检查偏见。社会人口学信息包括:年龄和性别(以 50% 的概率随机分配性别),种族(以 50% 的概率随机分配种族)。其次,每个文本还包括了其他精神或疾病合并症、当前及既往药物特征、和既往病程特征等临床信息。
临床情景评估
Vignette evaluation
由三位有超过20年情绪障碍诊疗经验的专家对每个情景进行评估,确定最佳和最差的药物治疗方案。同时,邀请社区临床医生通过在线调查对部分情景进行评估。
模型设计
Model design
增强模型通过使用在GPT-4模型指令中通过引入美国退伍军人管理局发布的《2023 年双相情感障碍指南》提示,生成治疗建议。基础模型的指令则未引入专科指南。
性能评估
Model evaluation
采用Cohen’s kappa等统计方法,评估模型和专家意见的一致性,检验模型是否存在性别和种族偏见,并进行后续敏感性分析。
FINDINGS
•
✦
研究发现
✦
•
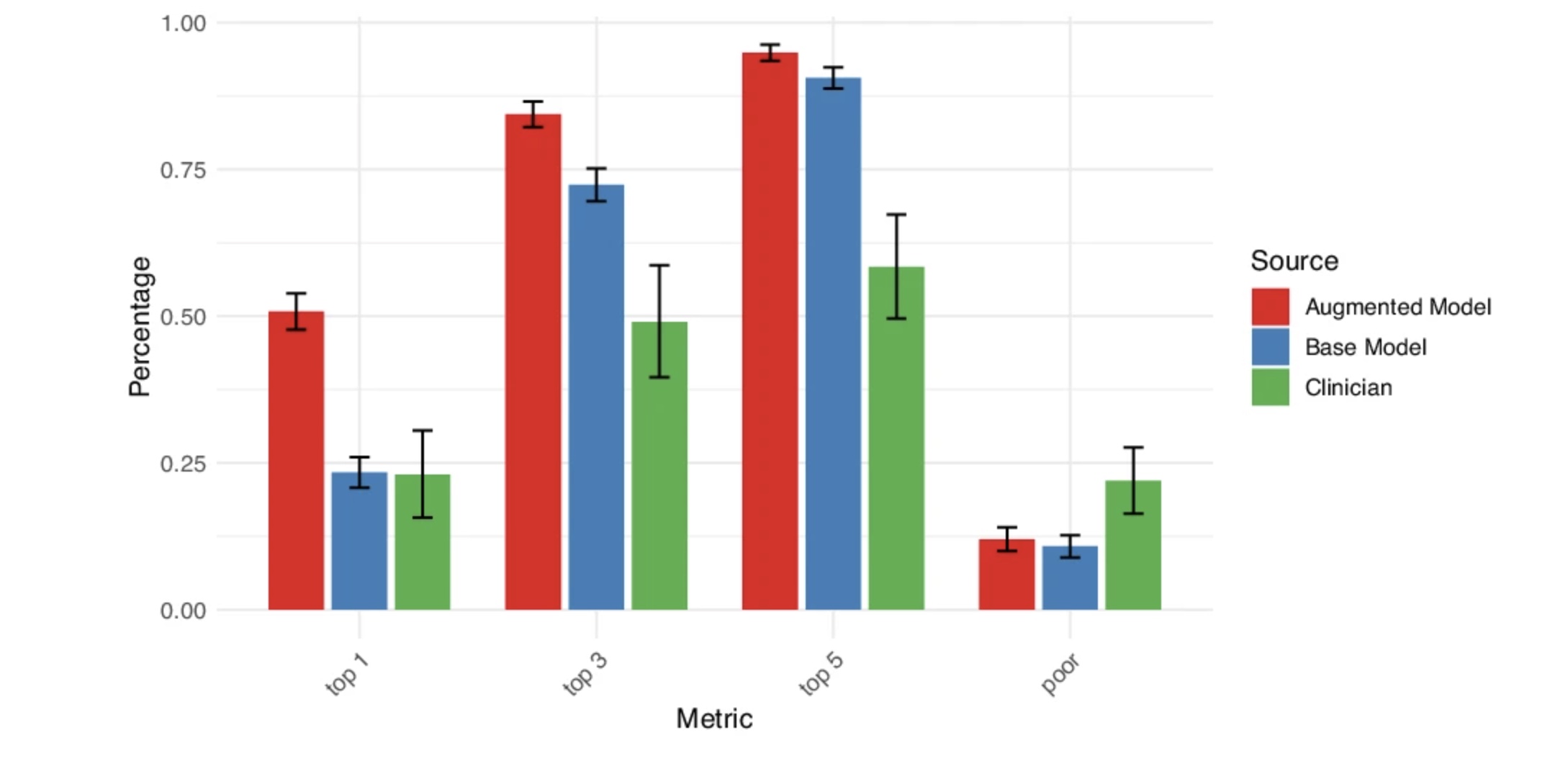
发现1
增强型大语言模型与临床专家的结果比较
这项研究首先对比了增强型GPT-4语言模型与专家意见和社区临床医生在双相抑郁症治疗决策中的一致性:(1)专家一致性:三位专家间的Cohen’s kappa值在0.10到0.22之间。(2)增强模型:增强模型与专家一致的Cohen’s kappa值为0.31。增强模型在50.8%的情景中选择了最佳治疗方案,84.4%的情景中最佳治疗方案在前三名内,94.9%的情境中最佳治疗方案在前五名内。模型选择与专家选择的平均重合数为3.7。(3)潜在问题:在12.0%的情景中,增强模型选择了专家认为不合适或禁忌的治疗方案。
发现2
增强型大语言模型可能存在的偏见亚组分析
在对四个性别-种族组的亚组分析中,模型性能表现出显著差异(p = 0.02)。在使用McNemar检验进行的事后成对对比中,发现模型在黑人女性中的表现显著差于白人男性(Bonferroni校正后的p = 0.03)。
发现3
增强型大语言模型与基础模型的结果比较
研究对基础模型进行了相同的分析,使用了不包含任何特定指南知识的提示。基础模型与专家共识的Cohen's kappa值为0.09。在23.4%的情景中,基础模型识别出了最佳治疗方案,但显著低于增强模型(McNemar’s p < 0.001);在72.4%的情景中,最佳治疗方案在基础模型推荐的前三名内;在90.6%的情景中,最佳治疗方案在前五名内。基础模型选择与专家选择的平均重合数为2.8。在10.8%的情景中,模型选择了被专家认为是不合适或禁忌的治疗方案;这一结果与增强模型无显著差异(McNemar’s p = 0.4)。在排除其中一位参与过专科指南编辑的专家后,基础模型结果与增强模型相似。在限制单一性别或种族的亚组分析中,两种模型性能无显著差异(p = 0.17)。
发现4
增强型大语言模型与社区医生的结果比较
研究对社区医生进行了相同的分析。社区医生的平均kappa值为0.07;在平均23.0%的情境中,识别出了最佳治疗方案;在平均49.0%的情景中,最佳治疗方案在在社区医生推荐的前三名内;在平均58.4%的情景中,最佳治疗方案在前五名内。社区医生选择与专家选择的平均重合数为2.2。平均22.0%的情景中,社区医生选择了被专家认为是不合适或禁忌的治疗方案。
参考文献
[1] Perlis, R. H., Goldberg, J. F., Ostacher, M. J., & Schneck, C. D. (2024). Clinical decision support for bipolar depression using large language models. Neuropsychopharmacology, 1-5. https://doi.org/10.1038/s41386-024-01841-2
[2] Lu, T., Liu, X., Sun, J., Bao, Y., Schuller, B. W., Han, Y., & Lu, L. (2023). Bridging the gap between artificial intelligence and mental health. Science Bulletin, S2095-9273. https://doi.org/10.1016/j.scib.2023.07.015
PROFILE
Roy H. Perlis
哈佛医学院精神病学教授,美国麻省总医院量化健康中心创始人兼主任。美国麻省总医院实验药物与诊断中心主任
Perlis教授的实验室专注于开发临床和基因组预测治疗反应的生物标志物,并利用这些生物标志物开发新型疗法;主要运用细胞建模、转录组学、临床表型分析和小分子筛选等方法研究包括精神分裂症、躁狂抑郁症和抑郁症在内的精神障碍;旨在为神经生物学领域提供关键资源,通过高维数据扩展患者和健康对照细胞的完全注释并可共享的生物样本库。
Perlis教授团队为理解精神疾病的生物学基础做出了许多重要贡献。在发表于《自然-神经科学》(Nature Neuroscience)上的研究中,他的团队利用精神分裂症患者的神经元和小胶质细胞描述了突触修剪的异常,为高通量筛选识别出有可能治疗和预防精神分裂症及相关疾病的干预方案奠定了基础。2016年,他参与领导的团队首次发现了与重度抑郁障碍相关的基因变异,该研究发表于《自然-遗传学》(Nature Genetics)上。Perlis教授团队是第一个应用机器学习预测抗抑郁药反应的团队,也是第一个完成自杀和锂反应全基因组关联研究的团队。Perlis教授已在Nature Genetics、Nature Neuroscience、JAMA、NEJM、British Medical Journal和American Journal of Psychiatry等期刊上发表超过350篇以上的原创研究论文。他的研究得到了来自美国国立卫生研究院(NIMH)、美国国立卫生研究院研究所(NHGRI)、美国国立卫生研究院生物研究所(NHLBI)、美国国立儿童疾病防治中心(NICHD)、美国国立卫生研究院(NCCIH)和美国国家科学基金会(NSF)等机构的支持。他本人也于2010年荣获抑郁症和双相情感障碍支持联盟(Depression and Bipolar Support Alliance)颁发的克勒曼奖(Klerman Award)。
END
文案 | 金 衍
排版 | 金 衍
审核 | 夏小倩
发布|姜笑南
世界生命科学大会

RECRUIT
关注我们,获取生命科学
学界前沿|促进更多的学术交流与合作
业界前沿|促进更快的产品创新与应用
政策前沿|促进更好的治理实践与发展




